|
Yeojin Song I'm a graduate student in Artificial Intelligence at Ewha Womans University, advised by Junhyug Noh. My research focuses on unlocking and properly leveraging the language capabilities of large language models — particularly in vision-language understanding, LLM reasoning, and building world models through video generation. |

|
Publications* denotes equal contribution. |
|
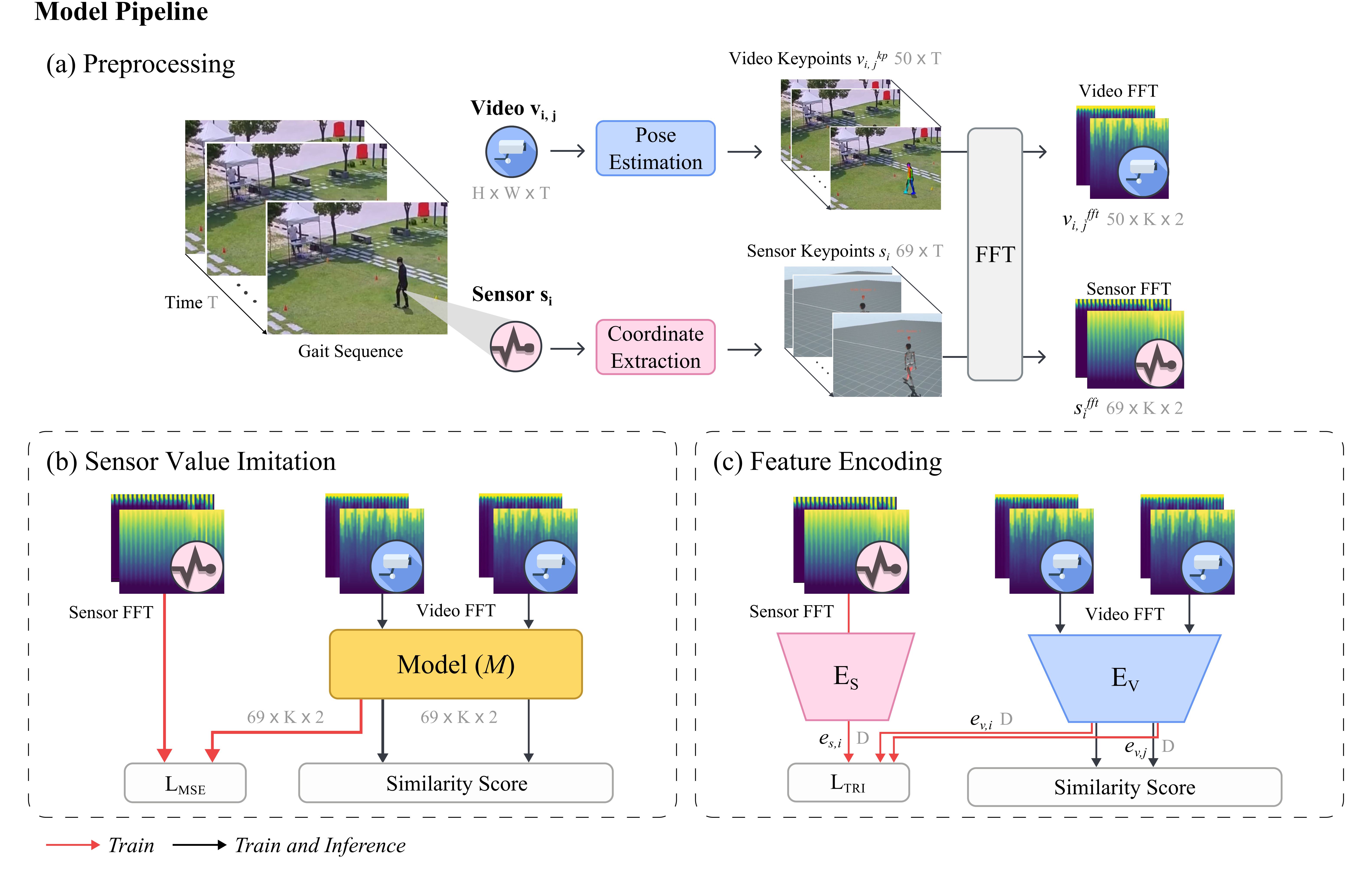
Towards Robust Gait Identification: A Frequency Domain Approach in Varied Surveillance Environments
Yeojin Song*, Luca Quagliato*, Sewon Jang, Egene Chung, Seoyeon Ko, Seoyeong Hwang, Junhyug Noh, Taeyong Lee IEEE Access, 2026 We propose a frequency domain-based gait recognition framework using FFT on openpose keypoints, integrating video and IMU sensor data. To support this, we introduce the E-GAITS dataset covering diverse surveillance conditions (indoor/outdoor, varying lighting). Our method achieves high recognition accuracy, with IMU integration particularly boosting performance in low-light environments. |
|
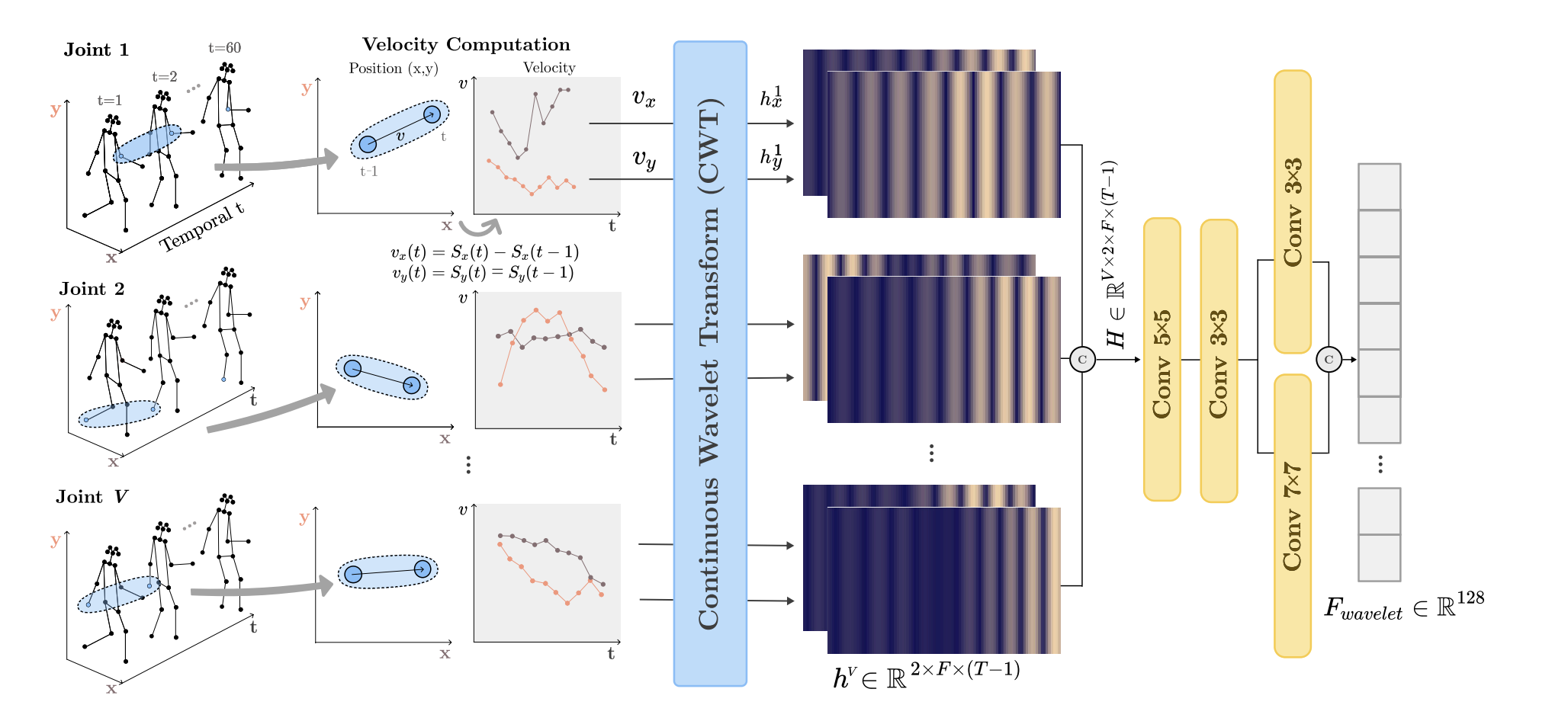
Explicit Time-Frequency Dynamics for Skeleton-Based Gait Recognition
Seoyeon Ko, Yeojin Song, Egene Chung, Luca Quagliato, Taeyong Lee, Junhyug Noh International Conference on Acoustics, Speech, and Signal Processing (ICASSP), 2026 We propose a plug-and-play Wavelet Feature Stream that enriches skeleton-based gait recognition by capturing time-frequency dynamics of joint velocities via Continuous Wavelet Transform (CWT). A lightweight multi-scale CNN extracts discriminative features from the resulting scalograms and fuses them with any existing backbone — requiring no architectural changes or extra supervision. The method consistently improves strong baselines on CASIA-B, with especially notable gains under covariate shifts like bag-carrying and coat-wearing conditions. |